מחקר: שכחה גורלית: אתגר עדכון ה-AI בסייבר - עדכון מודלים של AI לזיהוי קוד זדוני
מאת:
מערכת Telecom News, 25.3.21, 14:23

 הייפ נרחב מתפתח באחרונה סביב השימוש בבינה מלאכותית באבטחת סייבר. בפועל, התפקיד והפוטנציאל של AI באבטחה עדיין מתגבש ולעיתים קרובות דורש ניסוי ותהיה. אז איך זה עובד?
הייפ נרחב מתפתח באחרונה סביב השימוש בבינה מלאכותית באבטחת סייבר. בפועל, התפקיד והפוטנציאל של AI באבטחה עדיין מתגבש ולעיתים קרובות דורש ניסוי ותהיה. אז איך זה עובד?
הייפ נרחב מתפתח באחרונה סביב השימוש בבינה מלאכותית (
AI) באבטחת סייבר. בפועל, התפקיד והפוטנציאל של
AI באבטחה עדיין מתגבש ולעיתים קרובות דורש ניסוי ותהיה. אז איך זה עובד? ב-
SophosAI יצאו לבדוק.
זיהוי של קוד זדוני הוא הבסיס לאבטחת
IT, ו-
AI היא הגישה היחידה שמסוגלת ללמוד תוך מספר ימים תבניות פעולה על בסיסי מיליוני דוגמיות חדשות של קוד זדוני. אבל יש כאן מלכוד:
האם המודל צריך לשמור על כל הדוגמיות לעד כדי להשיג זיהוי אופטימלי, וזאת במחיר של לימוד ועדכון איטיים יותר.
או, שיש לבצע למידה בררנית, שתאפשר למודל להתמודד טוב יותר עם קצב השינויים בקוד הזדוני, אבל גם להתמודד עם סיכון של "שכחת" התבניות הישנות (הידוע גם כ-
catastrophic forgetting).
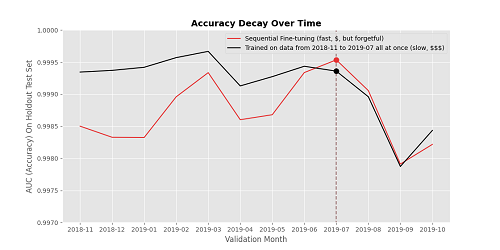
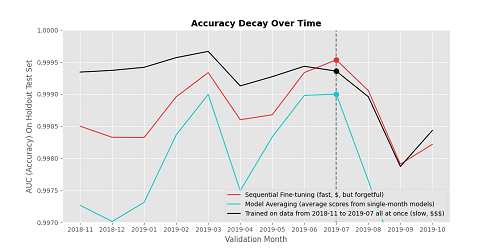
כאשר שומרים על המודל המלא עדכון אורך כשבוע, בעוד מודל, שעבר כוונון (
fine-tuning) נכון, יכול להתעדכן תוך שעה בלבד. בחברה רצו לבדוק אם אפשרי לבצע כוונון מדויק של מודל, שיוכל לעמוד בקצב השינוי של אופק האיומים, ללמוד תבניות חדשות ועדיין לזכור תבניות ישנות, תוך מזעור ההשפעה על ביצועים. החוקרת
הילארי סנדרס העריכה מספר של אפשרויות עדכון ופירטה את הממצאים שלה
כאן, ו
כאן.
דילמת הזיהוי
הצורך לשמור על יכולות הזיהוי מעודכנות הוא מאבק מתמשך. עם כל צעד, שאנו עושים לקראת הגנה מפני מתקפה זדונית, התוקפים כבר מפתחים דרכים חדשות כדי לעקוף אותו, כשהם מפרסמים עדכונים עם קודים וטכניקות שונות. התוצאה היא, שמאות אלפי דוגמיות קוד זדוני חדשות מופיעות בכל יום.
הזיהוי הופך לקשה אף יותר לאור העובדה, שהקוד הזדוני "החדש והנוצץ" הוא רק לעיתים קרובות באמת חדש. בד"כ, מדובר בשילוב של קוד חדש, ישן, משותף, או גנוב, עם התאמות בהתנהגות. יותר מכך, קוד זדוני ישן יכול להופיע מחדש אחרי שנים של היעלמות, ותוקפים משלבים אותו בארסנל הנשקים שלהם בעיקר כדי להפתיע. מה שאומר, שמודלים של זיהוי חייבים להמשיך ולזהות גם דוגמיות ישנות של קוד זדוני, ולא רק את החדשות והאחרונות.
עדכון מודלים של AI לזיהוי
כאשר יש לעדכן מודלים של
AI עם דוגמיות זיהוי חדשות, בפני ספקים עומדת בחירה בין 2 אפשרויות:
האחת, לשמור עותק של כל דוגמית, שהם אי פעם ירצו לזהות, ולהריץ את המודל שוב ושוב על כמות נתונים שתגדל לעד. הדבר מביא לביצועים טובים יותר אבל לעדכונים איטיים יותר.
השניה היא לעדכן את מודל הזיהוי רק בדוגמיות חדשות. הדבר ידוע כ-
fine-tuning. במהלך כל שלב בתהליך הכוונון, המודל מעדכן את ההבנה שלו בהתאם לידע שהתווסף, ויש לכך השפעה על סך התבניות. כתוצאה מכך, המודל עלול "לשכוח" תבניות ישנות, שהוא למד בעבר (
Catastrophic Forgetting). עם זאת, אימון מודל עם מידע מצומצם יותר מביא לעדכון מהיר יותר, ולפרסום עדכונים תכוף יותר, תוך עמידה בקצב השינוי המהיר של הקוד הזדוני.
בכל אפשרות שנבחר, הצורך לאמן את ה-
AI עם דוגמיות חדשות הוא תמיד קריטי. התבניות, שה-
AI לומד מתוך דוגמיות הקוד הזדוני, מאפשרות לו לבצע הכללה, וכך לזהות, לא רק את הקוד, שהוזן לו, אלא גם דוגמיות, שלא נצפו מעולם ושיש להן דימיון מסוים לדוגמיות האימון. עם זאת, לאורך זמן, הדוגמיות החדשות תישתננה בצורה כזו, שהיעילות של המודל הישן תרד ויהיה צורך לעדכנו.
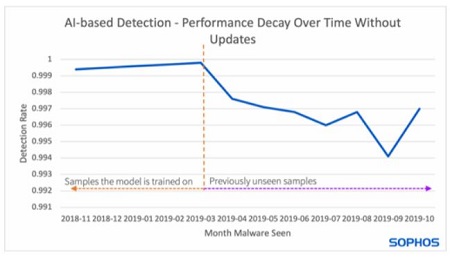
התרשים הבא מציג כיצד ביצועי זיהוי יורדים לאורך זמן אם המודל אינו מתעדכן בדוגמיות חדשות. בצד השמאלי מופיעות הדוגמיות הישנות שעל פיהן אומן המודל. שיעור הזיהוי גבוה באופן קבוע. הצד הימני מציג את הופעתן של דוגמיות חדשות, שהמודל לא אומן באמצעותן, ושיעור הזיהוי שלהן נמוך יותר.
3 אפשרויות הזיהוי, שהחוקרת בחנה הן:
1. לימוד מבוסס על מבחר של דוגמיות ישנות וחדשות. פעולה זו מכונה
data-rehearsal, והיא כולל מדגם קטן של דוגמיות ישנות בשילוב עם החדשות. בכך, "מזכירים" למודל את המידע הישן הנדרש כדי לזהות דוגמיות ישנות, ובמקביל מאמנים אותו כדי לזהות את החדשות.
2. שיעור הלימוד. גישה זו מתבססת על שינוי המהירות בה המודל "לומד" באמצעות הגבלת יכולות השינוי שלו לאחר שאומן עם כל דוגמית חדשה. עם שיעור לימוד מהיר מידי (ובמקרה זה המודל יכול להשתנות הרבה לאחר כל דוגמית שמתווספת), המודל "יזכור" רק את הדוגמיות האחרונות שראה. עם שיעור לימוד איטי מידי (המודל יכול להשתנות רק במעט בעקבות כל דוגמית שהתווספה) ייקח למודל הרבה זמן ללמוד משהו. מציאת היחס הנכון בין שיעור הלימוד, שימור מידע ישן והוספת מידע חדש, עלולה להיות משימה מאתגרת.
3. איחוד משקל אלסטי (
EWC). גישה זו פותחה בהשראת עבודה
DeepMind של גוגל ב-2017. היא כוללת שימוש במודל הישן כמו בקפיץ אלסטי כדי "למשוך לאחור" את המודל החדש אם הוא מתחיל "לשכוח". הסבר מעמיק יותר לגבי הדרך בה גישה זו פועלת ניתן למצוא
בפוסט של הילארי סנדרס.
ממצאים
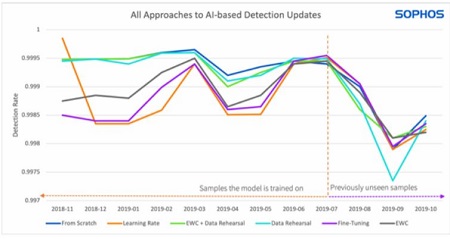
כל 3 הגישות הציגו תוצאות טובות יותר לגבי קוד זדוני ישן (משמאל לקו האנכי) מאשר לגבי דוגמיות חדשות (מימין)
גם הגישה האלסטית (
EWC) וגם שיעור הלימוד ביטלו את הצורך ואת העלות הקשורה בשימור נתונים ישנים. עם זאת, הגרף מראה, שבעוד הביצועים העתידיים (השימוש בנתונים חדשים) חזקים יותר מאשר בגישת
data-rehearsal, הם אינם מספקים ביצועים טובים יותר בכל הנוגע לזכרון של נתוני עבר.
מכיוון ש-
data-rehearsal מאפשרת אימון ועדכונים מהירים יותר
- במילים אחרות, הביצועים עוברים מהר יותר מהצד "הישן" לצד "המאומן" של הגרף, הירידה בביצועים העתידיים היא לטווח קצר יותר, ולכן מדאיגה פחות.
בס"ה, המחקר מראה, שגישת ה-
data-rehearsal מציעה את השילוב הטוב ביותר בין פשטות, מהירות עדכון וביצועים.
מסקנה -
במשחק זיהוי הקוד הזדוני, היכולת לזכור את העבר חשובה לא פחות מאשר לחזות את העתיד.
יש לאזן זאת מול העלות והמהירות של עדכון המודל במידע חדש.
Data-rehearsal היא דרך פשוטה ויעילה כדי להגן על היכולת של המודל לזהות קוד זדוני ישן, בעודה מגבירה באופן משמעותי את הקצב בו ניתן לעדכן ולפרסם מודלים חדשים.